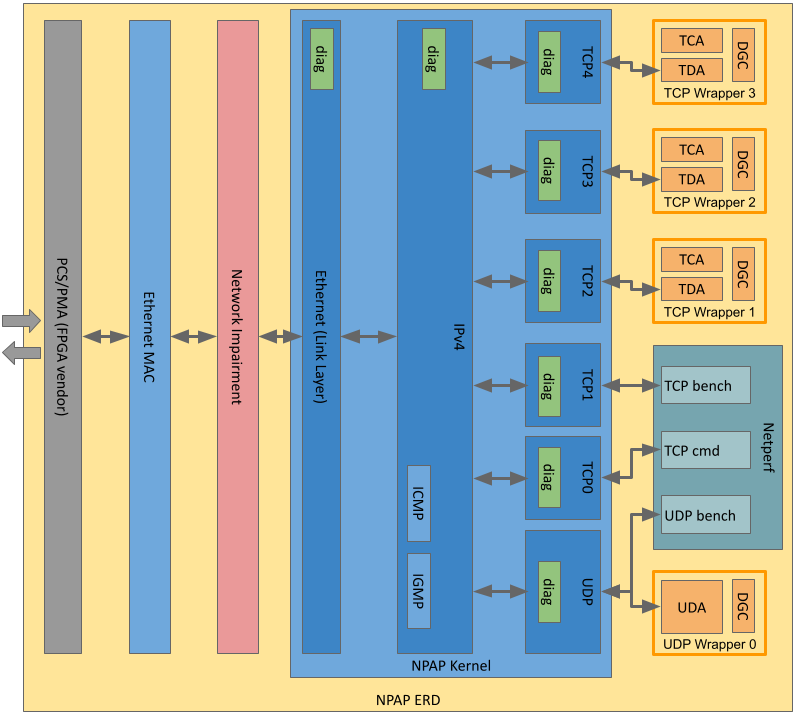
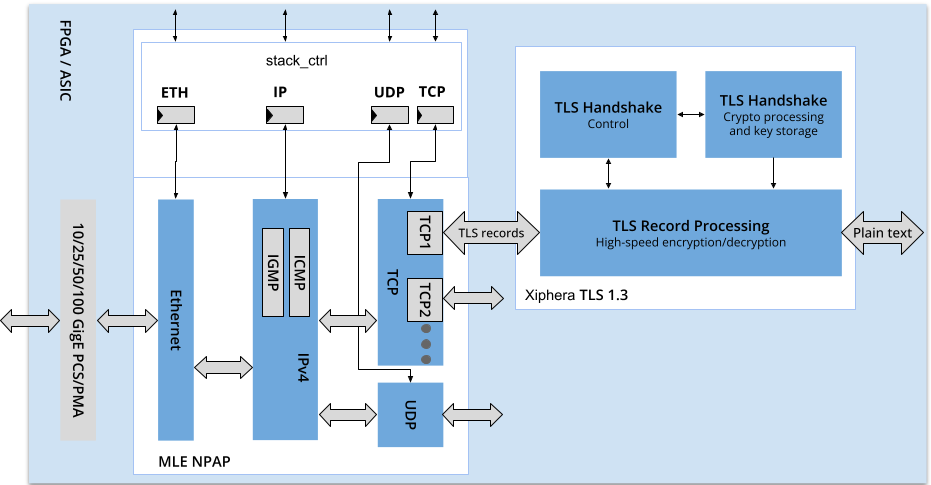
Here is the metric to determine TCP buffer sizes for NPAP (keep in mind, that TCP buffers are placed on both ends: Tx side and Rx side):
Buffer size (in bits) = Bandwidth (in bits-per-second) * RTT (in seconds)
RTT is the Round-Trip Time which is the time for the Sender to transmit the data plus the time-of-flight for the data, plus the time it takes the Recipient to check for packet correctness (CRC), plus the time for the Recipient to send out the ACK, plus the time-of-flight for the ACK, plus the time it takes the Sender to process the ACK and release the buffer.
For example:
- If the recipient is NPAP in a direct connection then we can assume ACK times less than 20 microseconds, i.e. buffer sizes shall be 200k bits. Means in this case a 32 kBytes on-chip BlockRAM per TCP session will be sufficient.
- If the recipient is software then RTT can be much longer, mostly due to the longer processing times in the OS on the recipient side. For a modern Linux we can assume RTT of 100 microseconds, or longer (see here [1] or run a ‘ping localhost’ on your machine). Means buffer sizes shall be around 1M bits, or the 128K Bytes of BRAM we typically instantiate.