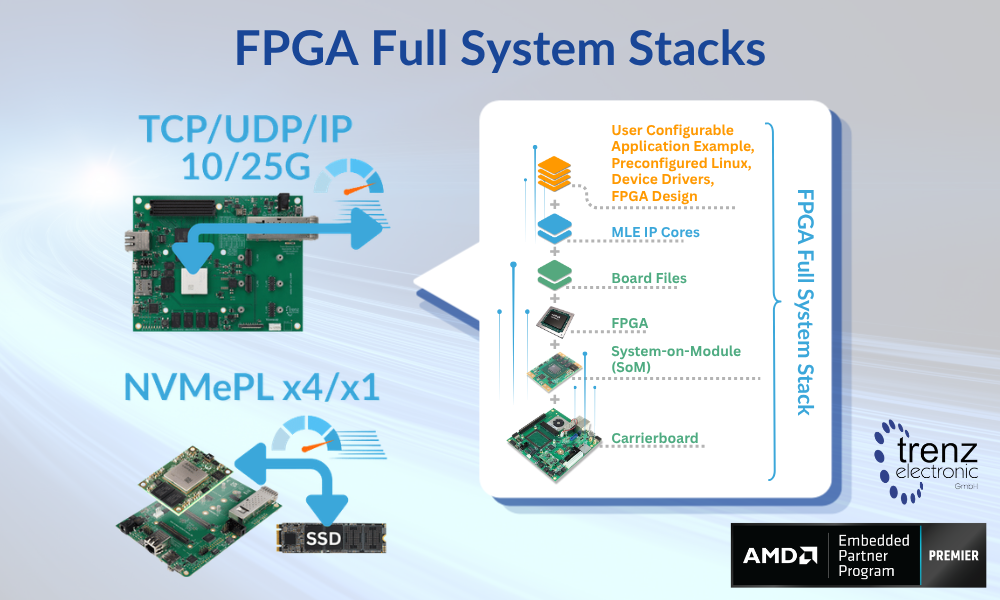
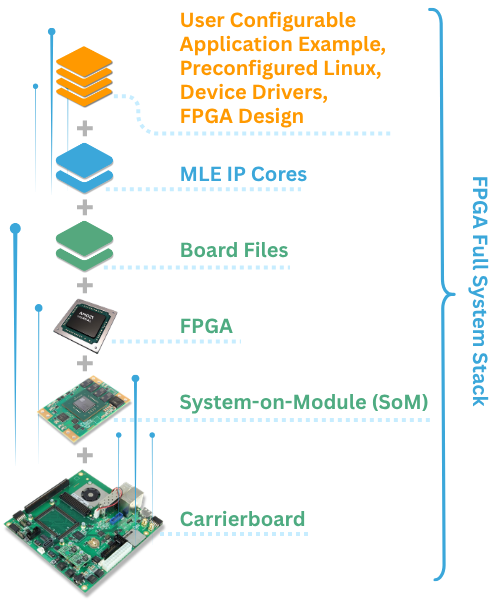
MLE Presents “Real-Time Networking with Stanford’s HOMA Protocol” at Storage Developers Conference 2026

The Storage Developers Conference (SDC) 2026 of SNIA, the Storage and Networking Industry Alliance, will be held Sept. 28-30 in Santa Clara, CA. There, MLE will present “Real-Time Networking with Stanford’s HOMA Protocol“.
At SDC 2023 and SDC 2024, we presented Homa, a reliable datacenter transport-layer protocol invented by John Ousterhout at Stanford University. We were able to demonstrate that Homa and TCP can co-exist in the same network “peacefully”, and how Homa can be accelerated by something similar to what Offload Engines do for TCP.
Today, (almost) everybody’s eyes are on datacenter infrastructure and AI clusters because of the challenging Terabit line rates and the high volume numbers of network ports. Nevertheless, there are many other applications which can also benefit from Homa:
- Systems-of-systems such as zone-based automotive networks
- Telecommunication core networks
- Converged IT/OT networks in industrial automation
- Backbones in humanoid robots
- Sensor Open Systems Architectures in aerospace & defense
These systems need a reliable transport-layer protocol which minimizes tail latency and optimizes infrastructure efficiency to deliver bandwidths of 10 Gbps, and more.
Many of these systems require hard real-time behavior which – in theory – matches with Homa’s attributes of being:
- message-based
- connection-less
- using receiver-driven congestion control
- run-to-completion (SRPT)
Time Sensitive Networking (TSN) has become the de-facto choice using IEEE standard Ethernet. TSN comes with time-synchronization, traffic shaping, reliability and resource management and works well with higher-layer protocols such as TCP.
Hence, in our presentation this year we will share insights on how Homa can be run over TSN and, in particular, the effects of different forms of traffic shaping on Homa’s core functions. We plan to start with a refresher on Homa and then dive into architecture choices when running TSN and multiple Gbps. This is complemented by presenting “Light Rabbit” which is a cost-optimized variant of CERN’s White Rabbit high-accuracy time synchronization which utilizes programmability of modern PLLs for frequency and phase synchronization to achieve nano-second accuracy. We close by presenting first experimental results of running Homa over TSN to achieve the best of both worlds.
Date: September 28-30, 2026
Session: File Systems & Protocols
Location: Hyatt Regency Santa Clara, Santa Clara, CA