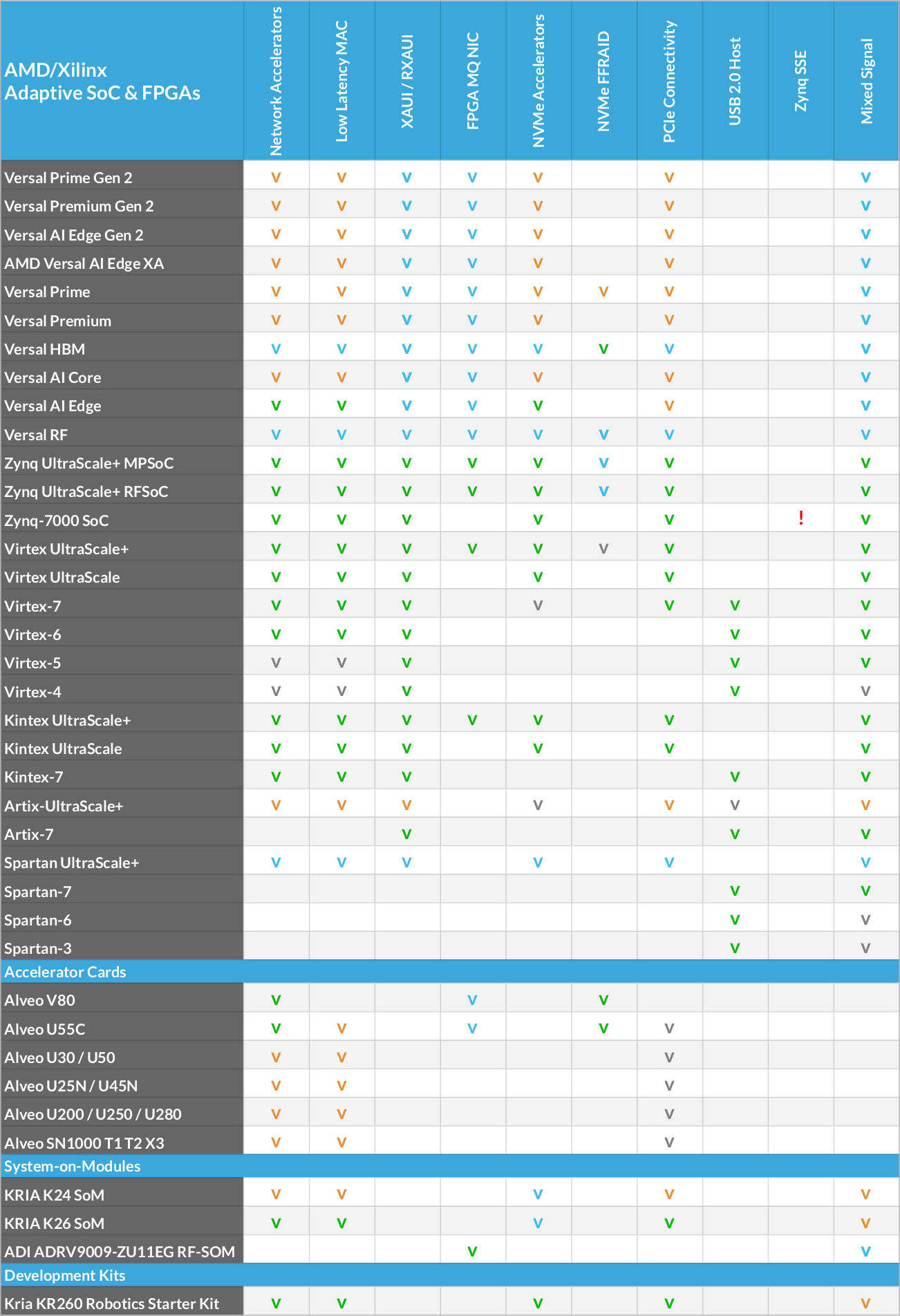
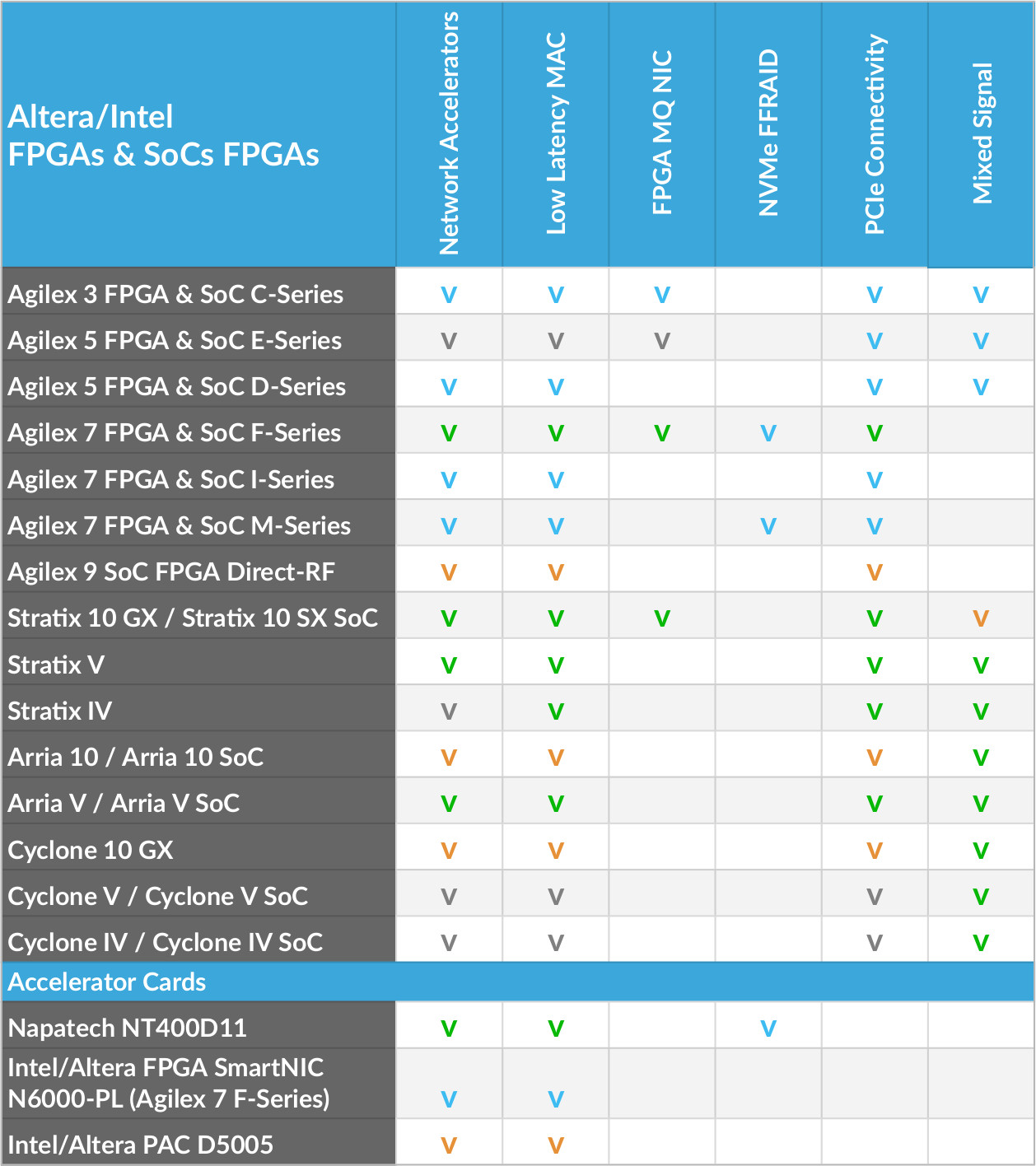
NVMe Fast FPGA RAID Accelerator
NVMe Fast FPGA RAID Accelerators
High-Speed Data Acquisition Systems, network telemetry analytics or broadcast recording systems, for example, do require storing massive data in non-volatile memory. For those cases where the read/write data rate exceeds the capabilities of even the highest performance NVMe SSDs, MLE has developed storage protocol accelerators for use with NVMe SSD RAID.

Now, you can transfer bulky data from multiple sensors to a RAID (Redundant Array of Inexpensive Drives) of NVMe SSDs at speeds up to 400 Gbps. MLE’s NVMe Fast FPGA RAID Accelerators (NVMe FFRAID) implement a channel-based architecture, support data-in-motion pre- and post-processing and are highly scalable with regards to bandwidth and recording capacity. Multiple systems can further be cascaded via IEEE 1588-2019 (HA) Precision Time Synchronization (PTP) for faster and/or deeper recording.
Adaptable signal front-ends support many different I/O standards in a “mix & match” fashion.
NVMe FFRAID is compatible with Linux Software-RAID (via the Linux MD driver). This allows recording at high data rates and replaying at slower speeds, or vice versa.
Channel-Based Architecture
NVMe FFRAID implements a channel-based architecture where each data source/sink can be associated with a dedicated RAID engine and a dedicated storage space. Each channel can have 10/25/50/75/100 Gbps, or combinations thereof.
This channel-based architecture along with the combination of FPGA-based NVMe acceleration plus a well-tuned PCIe setup, delivers a best-in-class price/performance ratio for high-speed data acquisition, recording and replay. MLE’s multi-core NVMe Host Controller Subsystem supports dedicated NVMe queues per SSD in a PCIe Peer-to-Peer communication.
Applications
- Autonomous Vehicle Path Record & Replay
- Automotive / Medical / Industrial Test Equipment
- Broadcast Recording
- High-speed Radar / Lidar / Camera Data Acquisition & Storage
- Network Telemetry and Analytics
- Very Deep Network Packet Capture of Ethernet or IPv4 or TCP/UDP Data
Key Features
- Scalable from 100Gbps to 400Gbps, or more
- Cascading of multiple systems with time-sync
- Start-Pause-Stop Data Recording
- Pre-trigger Data Recording in circular buffers
- Adaptable signal front-ends
- Striping mode (RAID 0)
- Striped and mirrored mode (RAID 0+1)
- Read/write compatible with Linux Software-RAID
- Compatible with TCG OPAL
Use Cases & Implementation Choices
NVMe FFRAID supports many off-the-shelf and custom FPGA boards and have been integrated by MLE partners into turnkey systems.


Altera Agilex-7 on Silicom ThunderFjord Card
- Agilex® 7 FPGA AGM032 / AGM039
- 2 x QSFPDD56 ports (50 GigE)
- Support data recording at 100/200/400 Gbps
- HBM2e options: 32GB, 16BG, No HBM2e
- DDR5 option: 4GB DDR5 ECC RAM (available to HPS)
- PCIe x16 Gen 5
- Dual slot passive heat sink (single slot option on request)

AMD Alveo™ V80 Compute Accelerator
- PCIe 5.0 x8x8x8x8
- Support data recording at 100/200/400 Gbps
- Many NVMe SSD options
- Customizable I/O front-end

AMD Alveo™ U55C High Performance Compute Card
- PCIe 4.0 x8x8
- Support data recording at 100/200 Gbps
- Many NVMe SSD options
- Customizable I/O front-end

Using custom or third-party FPGA cards?
Contact us to accelerate YOUR FPGA CARDS with NVMe FFRAID!
Scalability
NVMe FFRAID supports a wide range of NVMe SSDs and can be scaled from M.2 NVMe SSDs for small and light-weight embedded systems up to large 19” racks using high-performance U.2 or U.3 NVMe SSDs. Scalability also includes selecting from different SSD capacities and Drive-Writes-per-Day (DWPD) models. Here a table of possible recording times in minutes:
| Recording Speed (Gbps) | ||||||||
| Storage (TiB) | 100 | 150 | 200 | 250 | 300 | 350 | 400 | |
| 5 | 7.2 | 4.8 | 3.6 | 2.9 | 2.4 | 2.0 | 1.8 | |
| 10 | 14.3 | 9.5 | 7.2 | 5.7 | 4.8 | 4.1 | 3.6 | |
| 15 | 21.5 | 14.3 | 10.7 | 8.6 | 7.2 | 6.1 | 5.4 | |
| 20 | 28.6 | 19.1 | 14.3 | 11.5 | 9.5 | 8.2 | 7.2 | |
| 25 | 35.8 | 23.9 | 17.9 | 14.3 | 11.9 | 10.2 | 8.9 | |
| 50 | 71.6 | 47.7 | 35.8 | 28.6 | 23.9 | 20.5 | 17.9 | |
| 80 | 114.5 | 76.4 | 57.3 | 45.8 | 38.2 | 32.7 | 28.6 | |
| 100 | 143.2 | 95.4 | 71.6 | 57.3 | 47.7 | 40.9 | 35.8 | |
| 200 | 286.3 | 190.9 | 143.2 | 114.5 | 95.4 | 81.8 | 71.6 | |
| 500 | 715.8 | 477.2 | 357.9 | 286.3 | 238.6 | 204.5 | 179.0 | |
| Recording Time in Minute(s) | ||||||||
Data Acquisition Pre- and Post-Processing
Besides record/replay of raw data NVMe FFRAID supports data-in-motion pre- and post-processing that enables you to add your custom algorithms for indexing and metadata generation, on-the-fly data decimation, or running in “spy-mode” as a transparent data proxy.
Plain Recording, Loss-Less and Gapless

Ingress data from the high-speed sensors are transferred and recorded at-speed and as-is onto the NVMe FFRAID.
Data Proxy & Record

Communication from a high-speed data source can be transported to a data sink while this data is also recorded at-speed.
Data Decimation & Record

Unwanted pieces of the ingress data is removed on-the-fly prior to storage, certain regions-of-interest (ROI), for example.
Adding Meta-Data & Record

Ingress data can be analyzed on-the-fly to generate indexing information for later search, for example. This metadata is then recorded along with the ingress data. Metadata can, for example, be: Hardware timestamps, regions-of-interest, search indexes.
NVMe FFRAID is Linux Compatible
NVMe FFRAID is fully compatible with Linux Software-RAID (via the Linux MD driver). This allows recording at high data rates and replaying at slower speeds, or vice versa. For performance reasons, NVMe FFRAID stores your data as so-called Linux block storage, i.e. no filesystems are used which slow down data acquisition and/or retrieval. Hence, you can record via NVMe FFRAID and replay that same data from a Linux MDRAID, and vice versa:
“Simplex Record”
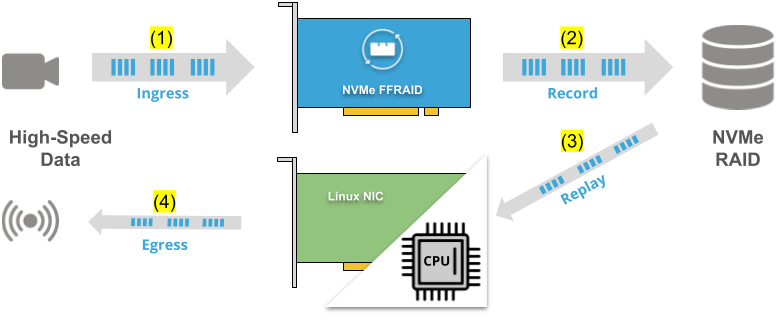
Ingress data (1) is recorded at high-speed using NVMe FFRAID (2). Once recording is done the NVMe FFRAID releases the SSD RAID and Linux opens this as an MDRAID. Then data can be replayed via Linux (3), typically at lower speeds, and, for example sent out via a Linux network connection (4).
“Simplex Replay”
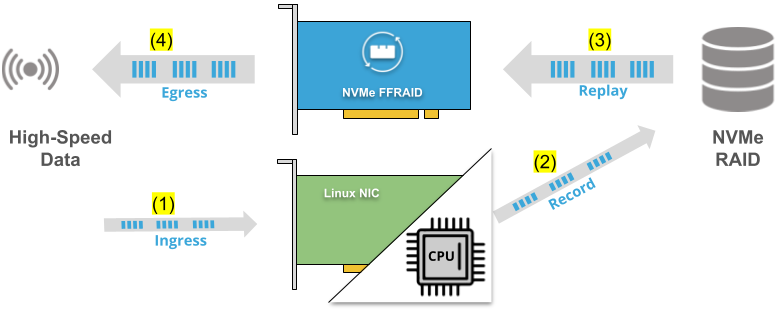
Ingress data (1) comes in via a Linux NIC, or any other Linux userspace software, for example, and is recorded onto a Linux MDRAID (2). Once recording is done, Linux releases the SSD RAID and NVMe FFRAID then opens it. Then data can be replayed via NVMe FFRAID (3) and be streamed-out at high data rates (4).
“Half-Duplex Record & Replay”
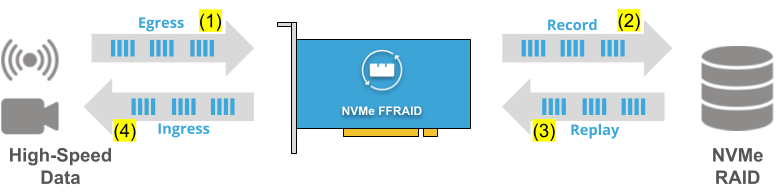
Ingress data (1) is recorded at high-speed using NVMe FFRAID (2). Once recording is done, then data can be replayed via NVMe FFRAID (3) and be streamed-out at high data rates (4). Because you operate the NVMe SSDs purely in sequential read (ex-or write), this features best performance.
“Full-Duplex Record & Replay”
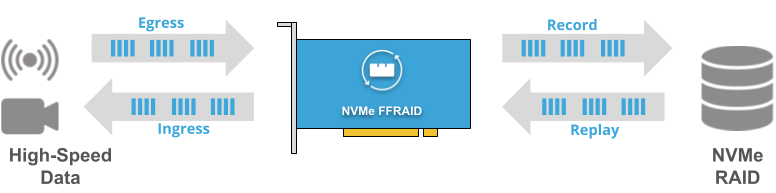
Ingress data is recorded at high-speed using NVMe FFRAID. At the same time, while recording, data is replayed from the NVMe FFRAID and be streamed-out at high data rates. Because typical NVMe SSDs deliver less performance when writes happen parallel to rads, you will experience less performance in this mode.
Availability & Pricing
NVMe FFRAID is available as IP cores (for select FPGA devices), as NVMe FFRAID Cards (for select off-the-shelf FPGA cards), and as NVMe FFRAID Recorder (a variety of turnkey system appliances from MLE or MLE partners).
| VistProduct Name | Deliverables | Example Pricing |
|---|---|---|
| Evaluation Reference Design (ERD) | For evaluation puposes, and upon request, we can provide ready-to-run loaner cards or systems based on our PCIe 4.0 or PCIe 5.0 implementation. | Upon Request |
| NVMe FFRAID Recorder System | A ready-to-use yet customizable turnkey system built by MLE or MLE partners where hardware, software and “gateware” is fully integrated and tested. Different formfactor choices from medium-sized embedded PC to 19″ rack mount, lab-use or ruggedized. You can bring your own SSDs, or choose SSDs from our many options depending on the storage capacity required. Learn more about MLE NVMe FFRAID Recorder offerings. | Starting at $24,800.- (depends on SSD performance and capacity) |
| NVMe FFRAID Card | Our NVMe FFRAID Cards are based on off-the-shelf 3rd party FPGA cards (such as AMD Alveo or Altera). Includes a Single-Project-Use netlist FPGA design license so you can alter the FPGA-based signal frontend. | Starting at $9,800.- |
| Intellectual Property (IP) Cores | Single-Project or Multi-Project Use for select FPGA devices; Modular and application-specific IP cores, and example design projects; delivered as encrypted netlist or RTL. |
Documentation
- NVMe Fast FPGA RAID Accelerator Datasheet (updated Oct 2025)
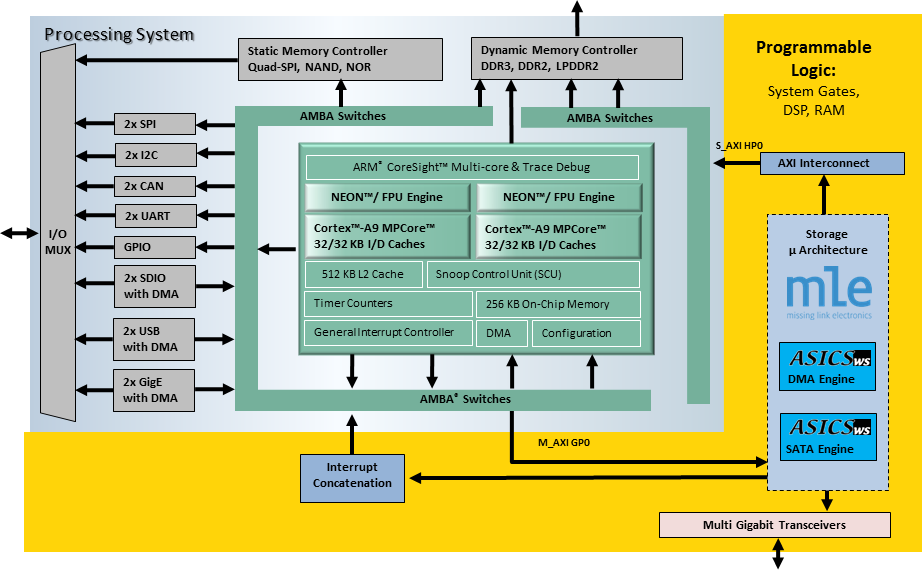
- System Architecture
- Exemplary Evaluation Reference Design
- FPGA Accelerator Card options
- SSD options
- Linux operating system choices
- FPGA Based 400GBit/s Data Recorder – Insight into Different Pitfalls and Design Choices
- Linux ZynqMP PS-PCIe Root Port Driver (A software-only, non-accelerated alternative described by the Xilinx Wiki)
- Example designs on GitHub from Opsero (for PS-based NVMe supporting various FPGA and MPSoC evaluation boards)
Frequently Asked Questions
Does the NVMe FFRAID support file systems?
No, the NVMe FFRAID uses so-called Block Storage. So, no file systems are not supported. For each data transfer the user application logic selects a start and maximum end address, and then data is written to flash in a linear fashion. This achieves best performance and avoids write amplifications.
Does the NVMe FFRAID support drive partitions?
Partitions are not explicitly supported. However, the user application logic can use the NVMe FFRAID to read the SSD’s partition table and then set up transfers with start and maximum end address to be aligned to partitions.
Does the NVMe FFRAID support NVMe namespaces?
Only one single namespace is supported per SSD.
How many SSDs can be connected to the NVMe FFRAID?
The standard for the NVMe FFRAID is 4/8/16 SSDs. The number of SSDs can be adjusted to your application within certain limits, for example: the accumulated sustained write speed should be faster than the incoming data stream, or too many SSDs can cause latency issues. However, we can customize the NVMe FFRAID for your application to support more complex PCIe topologies. Please ask us for more details.
How many NVMe IO Queues does the NVMe FFRAID support and what is the depth of the NVMe IO Queue?
NVMe FFRAID currently supports one single IO Queue per SSD. This IO Queue can have up to 128 entries, each with up to 128 KiB data. I.e. you can have up to 16 MiB of “data in flight” per SSD. If needed, we can change the depth and size of this IO Queue. However, given the needs of streaming applications increasing the number of IO Queues may not be advantageous.
Does the NVMe FFRAID support PCIe Peer-to-Peer?
Yes, this is supported. Peer-to-Peer transfers can be very attractive as it frees up the host CPU. Team MLE can customize the NVMe FFRAID for your application to support many more complex PCIe topologies, including multiple direct-attached SSDs, multiple SSDs connected via a 3rd party PCIe switch chip, including PCIe Peer-to-Peer. Please ask us for more details.
How many parallel streams can be processed?
Currently, the NVMe FFRAID handles 16 independent data streams. To save resources, the number of streams can be reduced without losing the overall performance by widening the data paths.
Does the NVMe FFRAID support M.2 PCIe connectivity?
Yes. Because the NVMe FFRAID is agnostic to the formfactor of your SSD M.2, U.2, U.3, EDSFF and so on are supported, as long as your SSD “speaks the NVMe protocol” and not SATA nor SAS.
What are the best SSDs to use and from which vendor?
While, again, the NVMe FFRAID is compatible to work with any NVMe SSD, there are a couple of other aspects to keep in mind when selecting an NVMe SSD: Noise, vibration, harshness, temperature throttling, local RAM buffers, SLC, MLC, TLC, QLC, 3D-XPoint, etc. To enable our customers to deliver dependable performance solutions, we have worked with a set of 3rd party SSD vendors and would be happy to give you technical guidance in your project. Please inquire.