Presentation at Automotive Ethernet Congress 2026, Munich, Germany, March 24-26, 2026
ADAS with coherent, multi-static, digital RADAR benefits from automotive Ethernet but demands more precise time synchronization and clock-phase recovery.
First we give an overview over time synchronization: NTP, GNSS, PTP, with a deep-dive into the PTP (including hardware assisted time stamping for accuracy and precision around 10 nanoseconds), down to the high-accuracy Precision Time Protocol IEEE 1588-2019 (PTP-HA) developed by CERN’s White Rabbit group for large scale physics experiments in need of < 1 ns accuracy and < 100 ps precision.
Second we present “Light Rabbit”, a collaboration between CERN and MLE. Using modern on-chip PLL for phase-shifting we complement (or replace) expensive VCXOs and trade-off BoM cost vs. minor loss of accuracy.
We close with experimental results for an OFDM RADAR network where Ethernet transports status, control and sensor data and distributes time (i.e. trigger), frequency and phase information to steer oscillators in the RF subsystem.
To learn more about the details, download the slides below or contact us for more information.
Presentation at Driving the Future Symposium 2025, Munich, Germany, Oct. 8-9, 2025
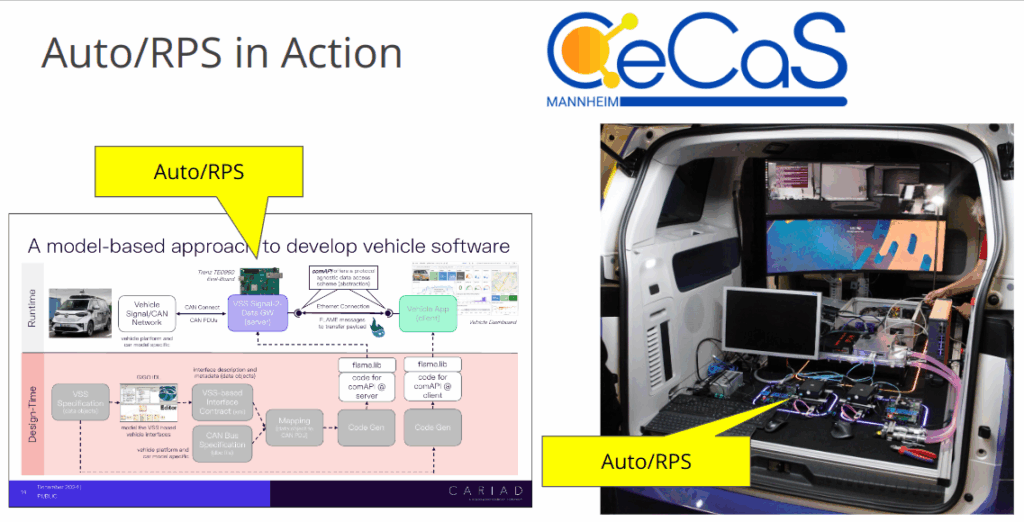
Modern Software-Defined Vehicle (SDV) architectures are pushing automotive in-vehicle networks towards more bandwidth and lower, guaranteed transport latency.
In the Symposium, work presented was intermediate results from joint research project “CeCaS,” which is co-funded by the German Bundesministerium für Forschung, Technologie und Raumfahrt. We also showcased how MLE and partner Trenz Electronic put together an Automotive Rapid Prototyping System (Auto/RPS) based on AMD’s Versal Edge AI devices to swiftly building the automotive networks in the CeCaS project.
To learn more about the details, download the slides below or contact us for more information.
Traditional PLCs have long been the backbone of industrial automation, but they come with significant limitations: high hardware costs, rigid scalability, complex maintenance, and vendor lock-in. Updating systems or adding new capabilities, AI for example, often means expensive hardware upgrades and downtime, while rolling out security patches across distributed devices is slow and risky. These challenges are particularly critical in real-time applications like robotics, motion, and CNC, where performance and jitter are essential.
To overcome these barriers, MLE and CODESYS have been working together to deliver a virtual control system that shifts control from local PLCs to cloud or remote servers for easier scalability, faster updates, and secure real-time communication, even for data-intensive industrial workloads.
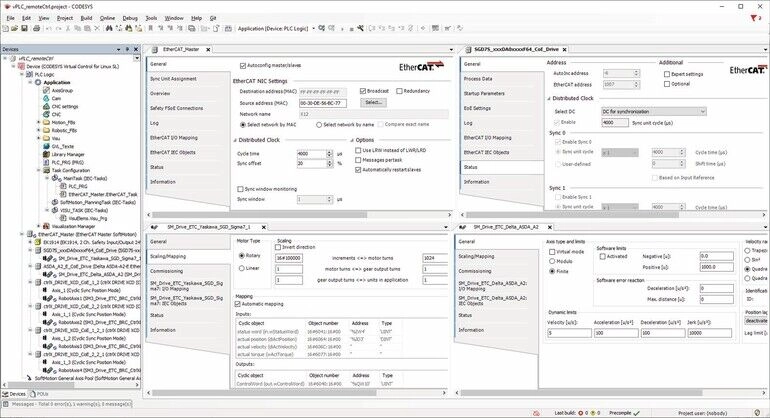
CODESYS virtual controllers bring flexibility with their software-based PLC system that eliminates the need for costly dedicated PLC hardware. They are easy to deploy, maintain, and update through its cloud-based, centralized PLC system, which allows rapid rollout of security patches and new features without downtime. Industrial users can manage coordinated motion and complex automation tasks with flexible, hardware-independent real-time control while using broad compatibility with fieldbus standards like EtherCAT and CANopen.
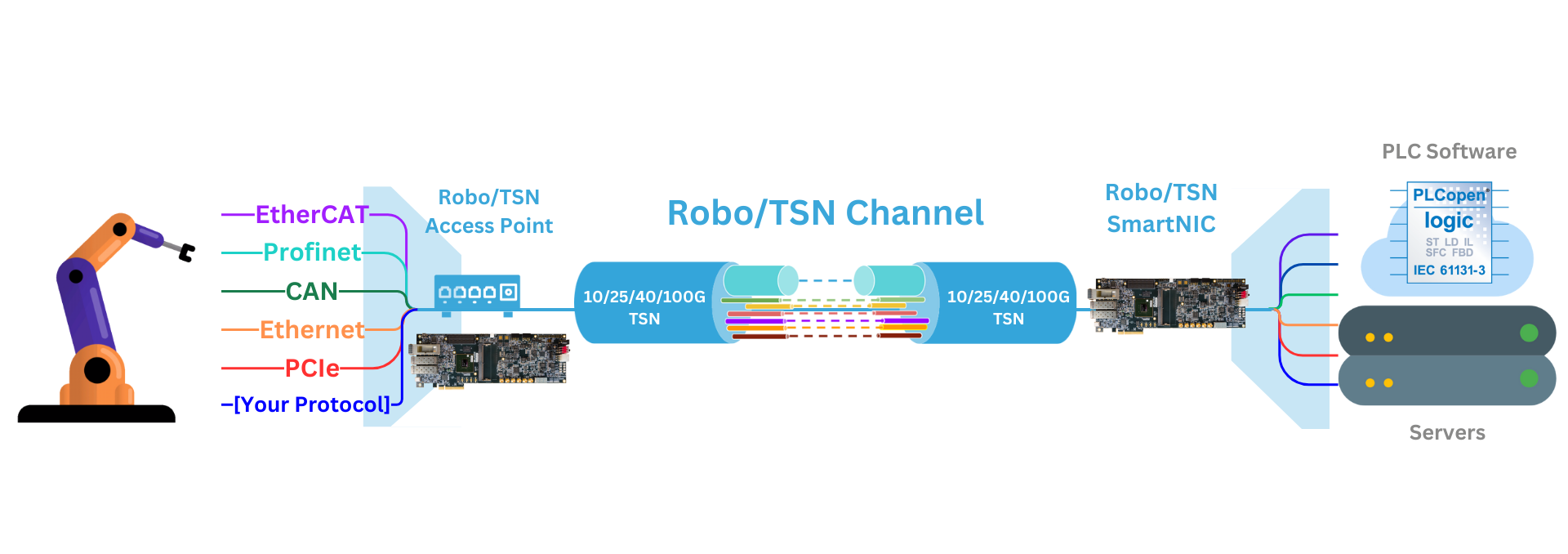
MLE Robo/TSN complements this capability by extending real-time, jitter-free communication between virtual controllers and distributed drives or I/Os over long distances. Using fiber optics and patented tunneling technology, Robo/TSN packetizes and transmits fieldbus data securely, fully compliant with IEC 62443 and compatible with functional safety protocols like FSoE and Profisafe, even in open IT networks. Most importantly, unlike other fiber optic systems, this data tunneling does not require any changes to existing PLC system configurations or operations. That enables CODESYS virtual controllers to maintain deterministic performance even when virtual controllers are hosted remotely.
The combination of CODESYS’ virtual control platforms and MLE’s Robo/TSN enable manufacturers to replace physical PLCs with secure, scalable virtual controllers hosted in datacenters, while maintaining high-performance, deterministic control for motion, CNC, and robotics tasks, even over distances exceeding 100 meters.
Key Benefits:
Simplified system maintenance and faster security rollouts
Reduced hardware complexity and costs
Easy performance scalability for motion, CNC, and robotics applications
Real-time, jitter-free control across extended distances (>100 m)
Real-time data transmission from 1 Gbps to 100 Gbps
Support for multiple protocols simultaneously (eg. PCIe, EtherCAT, Profinet, Ethernet, CAN, etc.)
This collaboration on virtual control technology paves the way for the next generation of resilient, secure, cost-efficient, and scalable industrial automation systems.
The CODESYS Group ranks among the world’s leading software manufacturers in the automation industry. The company´s main focus is the development and distribution of CODESYS, the well-known integrated IEC 61131-3 development environment (IDE) for controller applications and CODESYS Control, the platform independent runtime system.
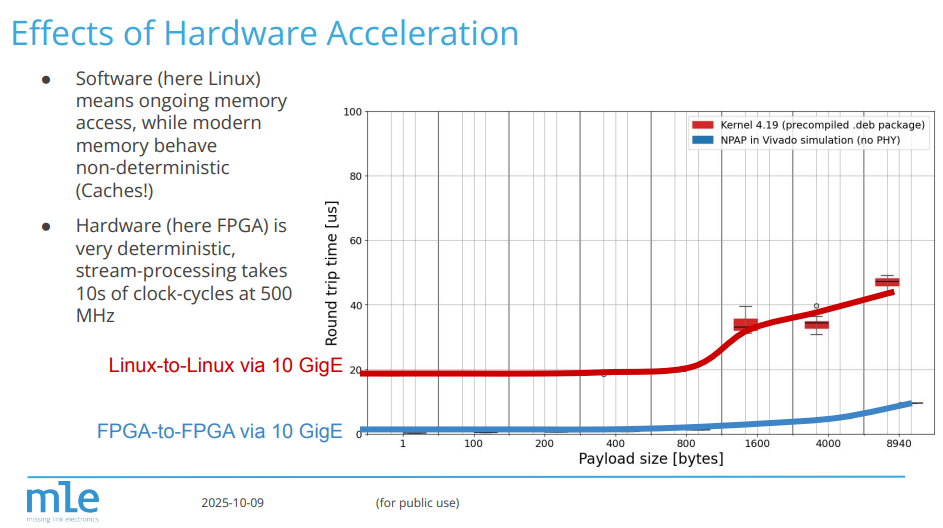
To meet the hard real-time requirements of modern motion control systems, MLE Robo/TSN uses hardware acceleration to implement secure “tunnels” which transport existing OT fieldbus protocols over standard IEEE TSN Ethernet.
Hence, you can add new connections without adding new wires!
MLE Robo/TSN is fully transparent to the PLC software and backwards compatible which demonstrated in SPS Magazin 9 2025 (P.31) as an enabler for virtualizing PLCs in a Factory Cloud.
Such virtualization gives better scalability and flexibility while allowing central maintenance and configuration. This improves Overall Equipment Effectiveness (OEE) and Development Time.
Unlike many legacy fieldbus protocols MLE Robo/TSN can use Post Quantum Cryptography (PQC) to secure data transfers and to protect against man-in-the middle attacks, for example.
Presentation at 6G Conference 2025, Berlin, Germany, July 3rd, 2025
GNSS is widely used for positioning and synchronization—particularly in applications, such as vehicles and drones, where merging recorded radar data and coordinating multiple nodes over-the-air is essential. Accurate time-stamping is crucial to ensure data integrity, which requires a reliable and common time source. However, GNSS connectivity can be limited or completely unavailable in challenging environments like tunnels or urban canyons, making precise synchronization difficult.
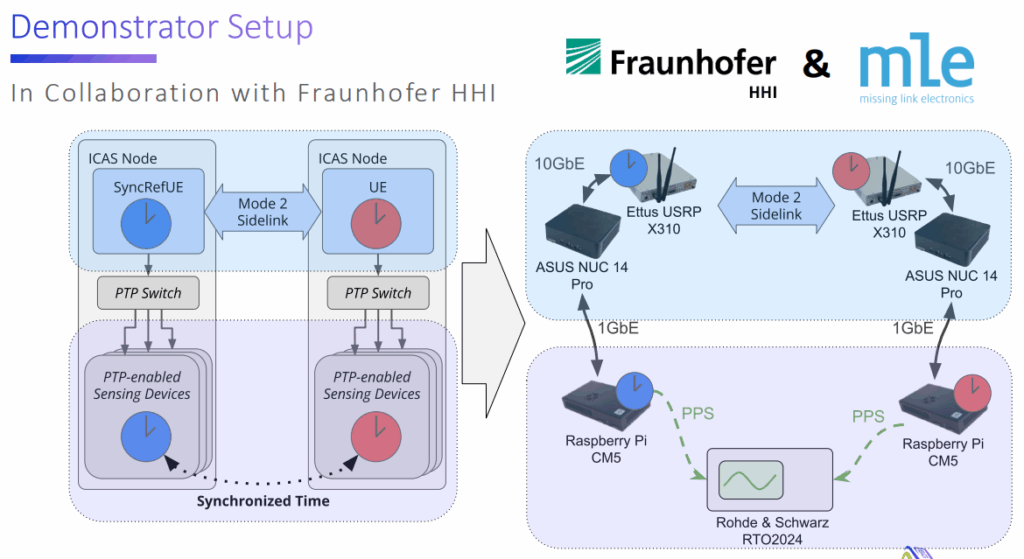
In this presentation, MLE showcases our approach to synchronize devices using PTP-based application layer time synchronization over 5G sidelink. We walk through the approach and implications of correlating PTP messages with 5G PHY layer frame timing, and briefly touch on a method for further improving the timestamp accuracy. In the end, we present our proof-of-concept demonstrator setup developed in collaboration with Fraunhofer HHI, along with initial experimental results, demonstrating microsecond-level time synchronization accuracy via PTP over 5G sidelink. Notably, this approach relies purely on existing mechanisms and requires no additional modifications to future 6G standards.
To learn more about the details, download the slides below or contact us for more information.
Presentation at the 14th White Rabbit Workshop 2025 at CERN in Geneva, Switzerland, Jun 25-26, 2025
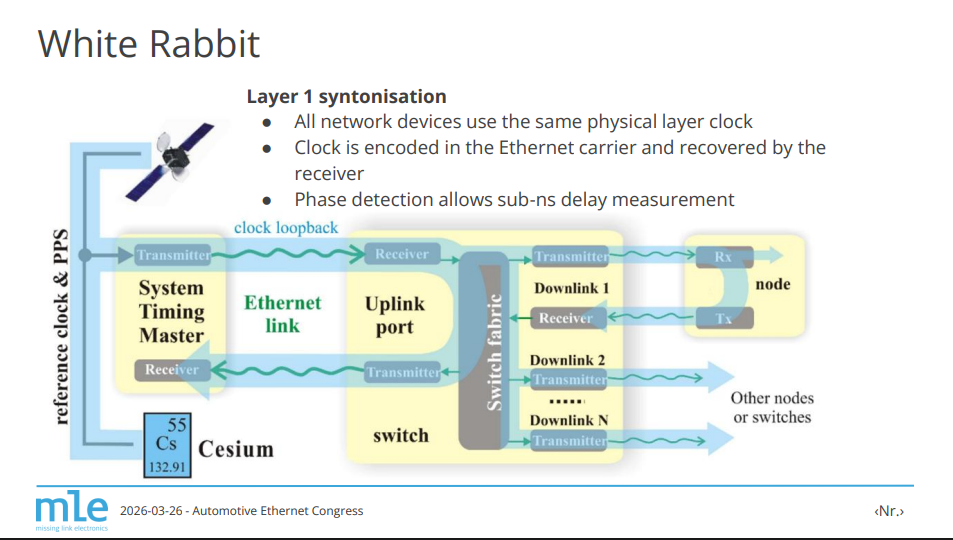
White Rabbit is a technology that allows to synchronize networked devices or endpoints tens of kilometers apart with a sub-nanosecond accuracy. It is now fully integrated into the IEEE1588-2019 or PTP v2.1 standard as high accuracy (HA) profile. Each endpoint employs frequency and phase measurement and adjustment techniques using field programmable gate arrays (FPGAs) and external voltage-controlled crystal oscillators (VCXOs). However, this usually requires external circuit boards with specific components, which is not available on commercially off-the-shelf (COTS) development boards.
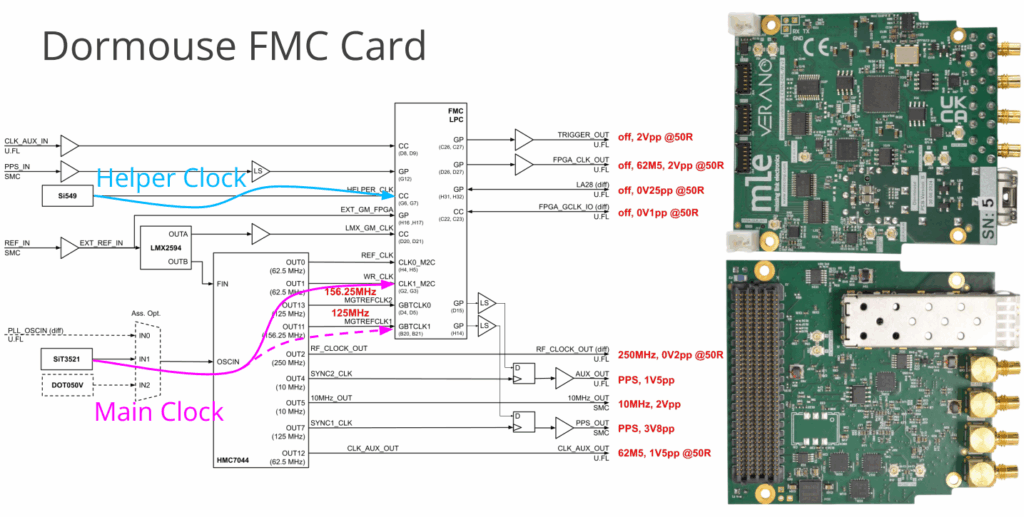
This talk provides an overview about the most major steps on White Rabbit within MLE. We present our journey with the Dormouse FMC, featuring tunable oscillators that are required to deploy and operate White Rabbit, and the enablement of it for AMD ZCU102, ZCU106, ZCU111 platforms. Based on this development a bistatic RADAR setup has been built together with and at KIT. The respective setup is also used in 6G massive MIMO experiments.
As a side effect of the Dormouse related developments some basic FMC Card support, SiT3521 operation, extensions to the HMC7044 CLI command, GTY transceiver support, etc. have been added, which currently wait for MRs to be opened.
In parallel a ZC706 and X310 based White Rabbit implementation has been put together using the PICXO approach, which is used in one of the research projects. The same project received refined GNSS support, which is publicly available as an MR already.
To enhance the accuracy of the AMD devkit based MLE WR nodes an initial absolute calibration session has been carried out together and at KIT.
We also provide a peek into our test infrastructure and an outlook into what we plan to achieve throughout the rest of this year.
To learn more about the details, download the slides below or contact us for more information.
Presentation at FPGA Conference 2025, Munich, Germany, July 3rd, 2025
In the decade of high-performance networking and computing, FPGAs have arisen as a promising and highly convenient solution, offering flexibility, reprogramming capacity and parallelism options. The role of high-performance solutions that offer a high throughput in network-related operations is extremely beneficial in real-time processing tasks executed on embedded systems, such as real-time video streaming.
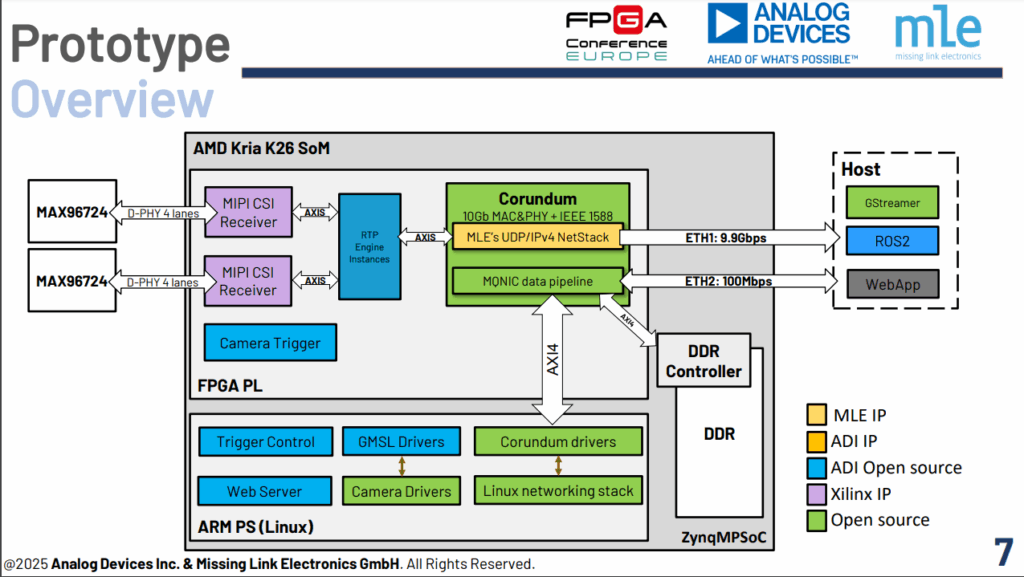
In this presentation, MLE and Analog Devices showcase the capabilities and obtained performance of our FPGA-based high-speed multi GMSL camera to RTP streaming solution using a single 10GbE link. There will be a walk through the multi GMSL Ser/Des integration, and the FPGA-powered components overview: the CSI-2 to RTP streams translation and the multi-GMSL camera synchronization, accompanied by the highly configurable and low-latency UDP/IP network accelerator. The described high-performance data path is integrated with the on-chip CPU subsystem to provide time synchronization via PTPv2 and enable control and monitoring of the device via the network. At the end of the presentation, we emphasize the most important design choices to build such a multi-camera streaming system. We finally draw the conclusions and the lessons learned from that successful experience.
Presentation at FPGA Conference 2025, Munich, Germany, July 3rd, 2025
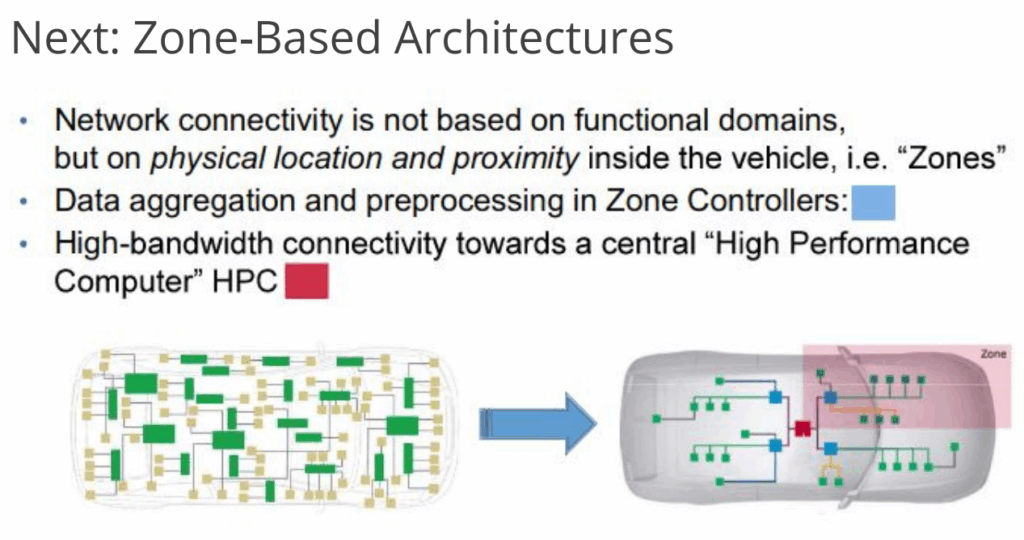
Automotive architectures are transforming: while more and more sensors become integrated in vehicles, the automotive industry is looking for ways to reduce wiring efforts in production, more scalability, higher level of integration and faster ways development.
Auto/TSN stands for automotive data over Time-Sensitive Networks which is an in-vehicle network infrastructure based on open standards such as IEEE Ethernet.
Auto/TSN virtualizes the in-vehicle network infrastructure: Key objective is to reduce costs, increase scalability and enable upgradability for next-generation automotive architectures including electric and/or autonomous vehicles.
The presentation will show how a zone based architecture can look like in comparison to the “classic” wiring. It will explain the tasks of a zone gateway and why FPGA/SoC play a major role in sensor fusion. Further more why it is important to use middleware which turns devices in a service for a central car server and other ECUs. For visualization, we will show examples of the government funded CeCaS research project and show the complete chain from camera sensors over zone gateways to the central car server.
Driven by the needs, and constraints, of the CeCaS Project MLE and partner Trenz Electronic have put together an Automotive Rapid Prototyping System (Auto/RPS) based on AMD’s Versal Edge AI devices.